这个星期状态不太好,只看了一篇 FCN 的论文和一些其他相关的资料。今天按照下面来总结一下关于语义分割的一些基础方面的内容。
- 什么是语义分割
- 什么是 FCN
- 如何构建全卷积网络
- 如何进行语义分割
- 如何提高上采样的精度
什么是语义分割
第一次看到 “语义分割” 这个词的时候会觉得很高深,且很容易和自然语言处理联系在一起。其实语义分割还是计算机视觉的内容。那么什么是语义分割?别看名字这么高级,其实就是像素级别的分类问题。即对一张图片中的每一个像素进行分类。下面是语义分割与图像分类,目标检测的区别:
图像分类(Image Classification):对图像内的对象进行分类(识别对象类别)。如,识别一张图像是猫还是狗。

目标检测(Object Detection):对图像内的对象进行分类和检测,且标出每个对象的边界框,如下所示。这就意味着不仅要识别出图像中的对象类别,还需要知道它们的位置和大小。

语义分割(Semantic Segmentation):对图像中的每个像素进行分类。这意味着每个像素都有一个标签。对语义分割模型来说,不仅要识别出汽车,道路,人等对象,还要标出每个对象的边界。因此,模型要具有像素级的密集预测能力。

什么是 FCN
FCN,即全卷积神经网络(Fully Convolution Networks),是 2014 年,由加州大学伯克利分校的 Long 等人提出的。该论文中对 AlexNet,VGG net 以及 GoogLeNet 进行了一些改造,改造成全卷积网络,并进行迁移学习,应用在语义分割任务上。
那什么是全卷积神经网络?顾名思义,就是网络中都是卷积层(包括池化层)的神经网络。一个 FCN 可以对任何大小的输入进行操作,并产生相应(可能重新采样的)空间维度的输出。
如何构建全卷积网络
知道了全卷积网络的定义,我们该怎么构建它呢?在 FCN 的论文中,将一些模型(如,VGG)最后几层的全连接层替换成卷积层,就能够构建一个全卷积网络。如下所示,上面部分的过程是图像分类,最后 3 层网络是全连接层。在分类过程中,图像经过卷积操作,缩小尺寸,后经过全连接层,输出一个图像的预测标签。而将该网络的最后 3 层全连接层,全都替换成卷积层,就得到一个全卷积网络。

该全卷积网络将会得到一个比输入图像要小的图像结果,且该结果通常是粗糙模糊的高维度特征图,常以热力图(heatmap)相称。想了解热力图生成的过程,可以查看这个练习:链接。
如何进行语义分割
在上面构建全卷积网络的过程中,我们知道将原网络的最后几层的全连接层替换成卷积层,会得到一个粗糙的高纬度特征图。如果要进行语义分割,即进行像素级别的分类的话,我们需要将图片还原成原图片的像素级别,然后逐个像素进行分类。在 FCN 的论文中,作者用了上采样(Upsampling)的方法,对全卷积网络的最后的输出结果进行上采样,然后再逐像素进行分类预测,就能训练一个端到端的语义分割模型。如下图所示:
![]()
图片来自:Review: FCN — **Fully Convolutional Network **(Semantic Segmentation)
下面来讲一讲上采样,上采样其实就是反卷积(deconvolution)的过程,FCN 的作者称其为向后卷积(backwards convolution)的过程。对图像进行卷积的过程是一个使图像尺寸变小的过程,而反卷积的过程就是上采样使图像尺寸变大的过程。反卷积这个名字经常会引起人们的误解,被认为是卷积的逆过程。其实不是的,它还是一种卷积的过程,有时也称为转置卷积(transposed convolution)。

如何提高上采样的精度
FCN 的论文中,如下图所示,在对 conv7 的输出结果进行 32x 上采样,得到与输入一样的尺寸大小。但是输出的结果还是不够精准,如下 FCN-32s 所示,将其与 Ground truth 相比,会发现结果还是太粗糙。为什么?因为在不断的增加深度的时候,可以得到深度的图像信息,但是也因为深度及池化的作用会损失空间信息。


后面论文作者使用了 _skip skip 的结构如下所示,就是一种融合输出的想法。将底层的信息和后面高层的信息结合起来,这样就会还原一些空间信息。
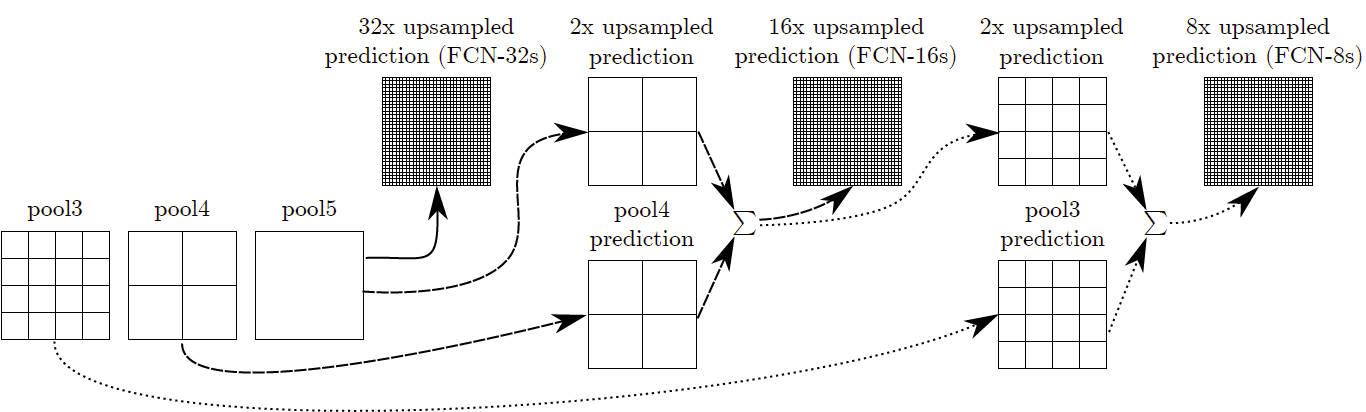
FCN-16s 的过程是,对 pool5 进行 2x 上采样,然后和 pool4 的预测结果融合再进行 16x 上采样。FCN-8s 是对 FCN-16s 的结果进行 2x 上采样,然后和 pool3 的预测结构融合再进行过 8x 上采样。后面实验得出 FCN-8s 的结果是最精确的。
以上就是关于 FCN 和 语义分割的内容。
参考
- https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1
- Fully Convolutional Networks for Semantic Segmentation Paper